Training Algorithm (Legacy)#
Note: The AReaL-lite approach is more recommended for new implementations due to its cleaner separation of concerns and better maintainability.
The legacy approach encapsulates algorithms in a ModelInterface with three core
methods:
# From realhf/api/core/model_api.py
class ModelInterface(abc.ABC):
"""Interface for model training, inference, and generation.
This interface follows the dependency injection pattern, allowing
algorithms like REINFORCE and PPO to use the same underlying model
while exhibiting different training behaviors.
"""
def inference(
self,
model: Model,
data: SequenceSample,
mb_spec: MicroBatchSpec,
) -> SequenceSample | None:
raise NotImplementedError()
def generate(
self,
model: Model,
data: SequenceSample,
mb_spec: MicroBatchSpec,
) -> SequenceSample | None:
raise NotImplementedError()
def train_step(
self,
model: Model,
data: SequenceSample,
mb_spec: MicroBatchSpec,
) -> Dict | List[Dict]:
raise NotImplementedError()
When the dataflow is fixed, you typically only need to modify the algorithm interface file.
Note: We recommend using asynchronous RL so you can customize generation behavior by modifying your RL agent instead of the
generatemethod.
Example 1: Grouped Advantage Normalization#
Let’s modify PPO’s global advantage normalization to use grouped normalization (GRPO approach).
Understanding Data Organization#
Each batch contains multiple prompts (batch size) and each prompt may have multiple responses (group size). So total sequences = batch_size × group_size.
Sequences have different lengths but are packed into a 1D tensor. We use cu_seqlens
(cumulative sequence lengths) to mark boundaries, similar to flash-attention.
Implementation#
The standard PPO normalization looks like:
@dataclass
class PPOActorInterface(ModelInterface):
def train_step(self, model: Model, data: SequenceSample, mb_spec: MicroBatchSpec) -> Dict | List[Dict]:
# ...
if self.adv_norm:
advantages = masked_normalization(advantages, loss_mask)
# ...
For grouped normalization, we partition advantages by group:
@dataclass
class PPOActorInterface(ModelInterface):
group_adv_norm: bool = False
def train_step(self, model: Model, data: SequenceSample, mb_spec: MicroBatchSpec) -> Dict | List[Dict]:
# ...
if self.adv_norm:
if not self.group_adv_norm:
advantages = masked_normalization(advantages, loss_mask)
else:
n_samples = data.bs
adv_list = []
for i in range(0, n_samples, self.group_size):
# Define chunk boundaries
s = short1cu_seqlens[i]
e = short1cu_seqlens[i + self.group_size]
# Extract advantages for this group
adv = advantages[s:e]
mask = loss_mask[s:e]
# Normalize within group
advn = masked_normalization(adv, mask, all_reduce=False)
adv_list.append(advn)
advantages = torch.cat(adv_list, 0)
# ...
Configuration Changes#
Update the experiment configuration to expose the new parameter:
@dataclasses.dataclass
class PPOMATHConfig(CommonExperimentConfig, PPOMATHExperimentOptions):
group_adv_norm: bool = False
@property
def rpcs(self):
# ...
actor_interface = ModelInterfaceAbstraction(
"ppo_actor",
args={
**copy.deepcopy(self.ppo_kwargs),
"group_adv_norm": self.group_adv_norm,
# ...
},
)
Example 2: Decoupled PPO Loss#
The decoupled PPO loss (from AReaL’s paper) recomputes probabilities before mini-batch updates and uses this as π_prox:
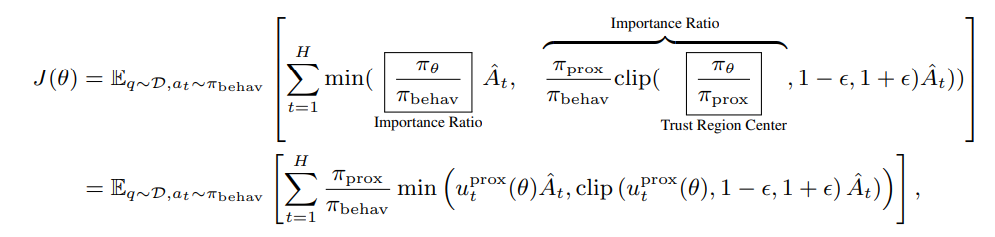
Probability Recomputation#
We recompute probabilities using the existing inference method:
@dataclass
class PPOActorInterface(ModelInterface):
use_decoupled_loss: bool = False
def train_step(self, model: Model, data: SequenceSample, mb_spec: MicroBatchSpec) -> Dict | List[Dict]:
if self.use_decoupled_loss:
s: SequenceSample = self.inference(model, data, mb_spec)
prox_logp = s.data["logprobs"]
# Prepare mini-batch data
flat_data = dict(
advantages=advantages,
old_logp=old_logp,
ppo_loss_mask=loss_mask,
packed_input_ids=input_.data["packed_input_ids"],
kl_rewards=kl_rewards,
)
if self.use_decoupled_loss:
flat_data["prox_logp"] = prox_logp.float()
flat_input = SequenceSample.from_default(
ids=list(range(input_.bs * self.group_size)),
data=flat_data,
seqlens=[int(x) for x in input_lens.cpu().numpy().tolist()],
)
# Split into mini-batches and train
datas = flat_input.split_with_spec(spec)
for mb_i, data in enumerate(datas):
train_stat = module.train_batch(
input_=data,
mb_spec=mb_spec,
version_steps=model.version.global_step,
loss_fn=_loss_fn,
loss_weight_fn=lambda x: x.data["ppo_loss_mask"].count_nonzero(),
token_normalize_scope=self.token_normalize_scope,
)
Modifying the Loss Function#
Update the loss computation to use the recomputed probabilities:
def _ppo_actor_loss_from_model_outputs(
logits: torch.FloatTensor, # [tot_seqlen, vocab_size]
input_: SequenceSample,
...
) -> torch.Tensor:
# ...
prox_logp = input_.data.get("prox_logp")
loss, ppo_stat = ppo_functional.actor_loss_fn(
logprobs=logprobs,
old_logprobs=old_logp,
advantages=advantages,
eps_clip=eps_clip,
loss_mask=ppo_loss_mask,
c_clip=c_clip,
proximal_logprobs=prox_logp,
behav_imp_weight_cap=behav_imp_weight_cap,
)
And in the core loss function:
def actor_loss_fn(
logprobs: torch.FloatTensor,
old_logprobs: torch.FloatTensor,
advantages: torch.FloatTensor,
eps_clip: float,
loss_mask: Optional[torch.BoolTensor] = None,
c_clip: Optional[float] = None,
proximal_logprobs: Optional[torch.FloatTensor] = None,
behav_imp_weight_cap: Optional[torch.FloatTensor] = None,
) -> Tuple[torch.Tensor, Dict]:
# Use proximal probabilities if available, otherwise use old probabilities
denorm_logprobs = proximal_logprobs if proximal_logprobs is not None else old_logprobs
loss_mask_count = loss_mask.count_nonzero() or 1
# Compute importance weights
ratio = torch.where(loss_mask, torch.exp(logprobs - denorm_logprobs), 0)
# Apply behavioral importance weighting for decoupled loss
if proximal_logprobs is not None:
behav_kl = proximal_logprobs - old_logprobs
behav_imp_weight = behav_kl.exp()
behav_kl = torch.where(loss_mask, behav_kl, 0.0)
behav_imp_weight = torch.where(loss_mask, behav_imp_weight, 0.0)
pg_loss = pg_loss * behav_imp_weight
# ...
return pg_loss, stat
Configuration Update#
@dataclasses.dataclass
class PPOMATHConfig(CommonExperimentConfig, PPOMATHExperimentOptions):
use_decoupled_loss: bool = False
@property
def rpcs(self):
# ...
actor_interface = ModelInterfaceAbstraction(
"ppo_actor",
args={
**copy.deepcopy(self.ppo_kwargs),
"use_decoupled_loss": self.use_decoupled_loss,
# ...
},
)