REINFORCE Leave-One-Out (RLOO)#
Last updated: Sep 28, 2025
Author: Honghua DONG
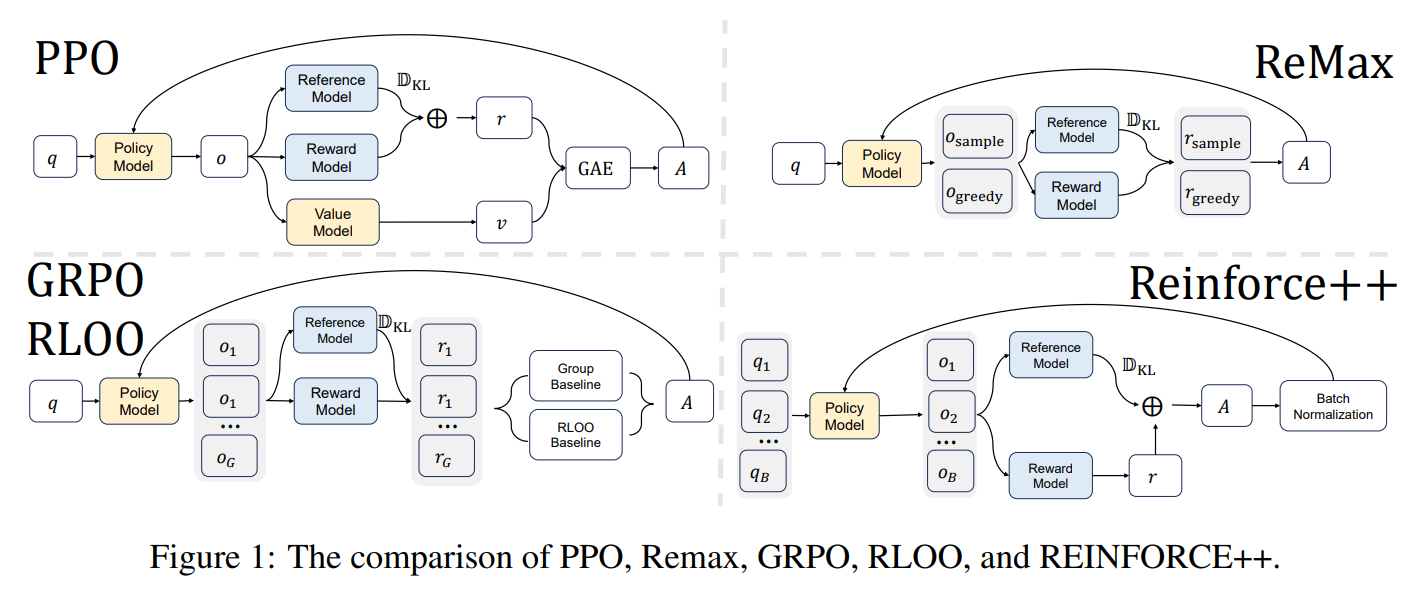
REINFORCE Leave One-Out (RLOO), introduced by Ahmadian et al. (2024), is an RL method that removes the need for a value function (critic). Instead, it estimates the baseline by averaging rewards of other sampled responses for the same prompt within the group.
The overall core objective is:
where: $\( \hat{A}_{i,t} = r_{i} - \frac{1}{G-1} \sum_{j\neq i} r_{j}. \)$
For more details:
AReal Detail: Paper of AReal
RLOO Detail: Paper of RLOO
Algorithm Core Parameters#
We only list the different parameters from GRPO here:
actor.adv_norm.mean_level: The level when calculate the mean of advantage. options:group,batchornone. In rloo, it is set togroupby default.actor.adv_norm.mean_leave1out: Whether to use leave-one-out average. In rloo, it is set totrueby default.actor.adv_norm.std_level: The level when calculate the std of advantage. options:group,batchornone. In rloo, it is set tononeby default.
Example Usage#
We recommend to change the parameter within the configuration file (i.e.gsm8k_rloo.yaml).
Backend |
CMD |
|---|---|
local |
|
ray |
|
slurm |
|
Baselines#
We still lack baseline, welcome to contribute!