Group Relative Policy Optimization (GRPO)#
Last updated: Sep 11, 2025
Author: Ziyi ZENG
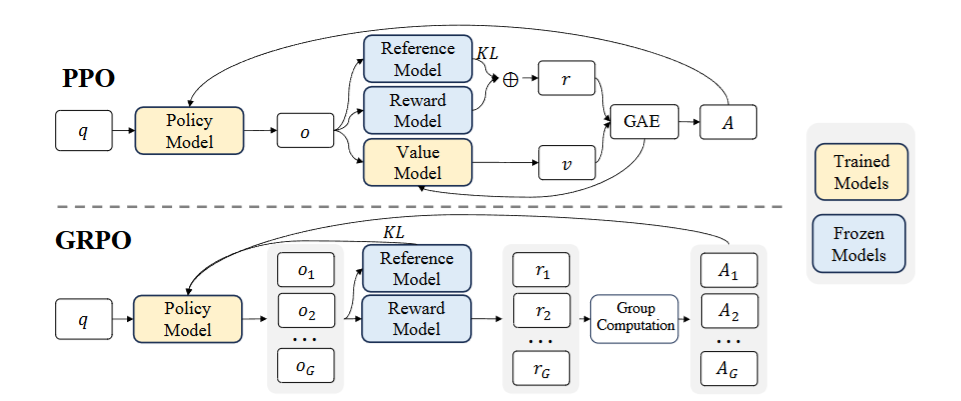
Group Relative Policy Optimization (GRPO), introduced in DeepSeekMath (Shao et al., 2024), is an RL method that removes the need for a value function (critic). Instead, it estimates advantage by normalizing rewards within a group of sampled responses for the same prompt. This normalization emphasizes differences between candidate outputs, preserving the reliability of the gradient signal even when rewards are sparse.
The overall surrogate objective is:
where: $\( r_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t} \mid q, o_{i,<t})}{\pi_{\theta_{\text{old}}}(o_{i,t} \mid q, o_{i,<t})}, \hat{A}_{i,t} = \frac{r_i - \text{mean}(\{R_i\}_{i=1}^G)}{\text{std}(\{R_i\}_{i=1}^G)}. \)$
For more details:
AReal Detail: Paper of AReal
GRPO Detail: Paper of DeepSeekMath
Algorithm Core Parameters#
actor.group_size: The number of groups to divide the sampled responses into.actor.path: The path to the actor model.ref.path: The path to the reference model (if using a reference model).kl_ctl: The coefficient for the KL divergence term in the objective.total_train_epochs: The number of epochs to train the model for.optimizer.lr: The learning rate for the optimizer.
Example Usage#
We recommend to change the parameter within the configuration file (i.e.gsm8k_grpo.yaml).
Backend |
CMD |
|---|---|
local |
|
ray |
|
slurm |
|
Baselines#
We still lack baseline, welcome to contribute!