Ming-Omni-TTS: 一种简单高效、可精确控制的语音、音乐和声音统一生成模型
· 阅读需 27 分钟
GITHUB 🤗 Hugging Face| 🤖 ModelScope
Ming-Omni-TTS的视频展示
🚀 技术亮点
Ming-omni-tts 是一款高性能的统一音频生成模型,不仅能精确控制语音的各种属性,还能在单一通道中合成语音、环境音效乃至音乐。其核心技术在于一个定制的 12.5Hz 连续型分词器和创新的逐块压缩方案,这使得模型在保持高质量的同时,实现了高达 3.1Hz 的推理效率。特别值得一提的是,Ming-omni-tts 拥有强大的文本归一化功能,即使是复杂的数学公式和化学表达式,也能进行准确而自然的朗读。
- 🔊 精细化语音控制: 通过简单的指令即可精确控制语速、音高、音量、情感和方言。在方言控制上,粤语准确率达到93%;在情感控制上,准确率达到46.7%,均优于 CosyVoice3 模型。
- 🌌 智能化声音创造: 内置100+高品质音色,并支持通过自然语言描述进行零样本音色创造。在 Instruct-TTS-Eval-zh 基准测试上的性能与 Qwen3-TTS 模型相当。
- 🎶 沉浸式统一生成: 业界首个在单一通道内联合生成语音、环境音和音乐的自回归模型。基于定制的 12.5Hz 连续分词器和 DiT 头架构,提供无缝的"身临其境"听觉体验。
- ⚡ 高效推理: 引入"逐块(Patch-by-Patch)"压缩策略,将 LLM 推理帧率降至 3.1Hz。显著降低延迟,支持播客式音频生成,同时保持自然度和音频细节。
- 🧪 专业文本规范化: 模型能够准确解析并朗读复杂格式,包括数学表达式和化学方程式,确保专业应用场景下的自然听感输出。
模型结构
Ming-omni-tts 基于统一连续音频分词器,用于语音、音乐和声音生成的统一音频语言模型。
统一连续音频分词器模型结构图

统一音频语言模型结构图

Benchmark 评测结果

语音控制 – 支持结构化和自然指令控制
基础属性控制:语音生成的速度、音量和音调控制
| Input Prompt | Target Text | Instruction1 | TTS Result | Instruction2 | TTS Result |
|---|---|---|---|---|---|
| 导航开始,全程二十五公里,预计需要十二分钟。 | 语速:慢速 | 语速:快速 | |||
| 烟雨弥漫下,山环绕着水耸立着,水环绕着山流淌着。 | 语速慢一点 | 语速快一点 | |||
| 目前共享出行市场处于高速增长阶段。 | 音量:低 | 音量:高 | |||
| 北京在出行规模,城市影响力方面表现优异。 | 音量尽量低一点 | 音量尽量高一点 | |||
| 他们脱掉笨重的冬衣,走起路来腰杆挺直步履轻盈。 | 基频:低 | 基频:高 | |||
| 自动驾驶将大幅提升出行安全,效率。 | 基频低一点 | 基频高一点 |
同方言/跨方言控制:根据普通话或母语提示生成粤语和四川语
| Instruction | Input Prompt | Conversion Type | Target Text | TTS Result |
|---|---|---|---|---|
| 方言:广粤话 | 广粤话 -> 广粤话 | 佢系头大冇脑脑大生草种 | ||
| 方言:广粤话 | 广粤话 -> 广粤话 | 今个周末全场货品低至五折,数量有限,卖晒就冇喇。 | ||
| 请用广粤话表达 | 广粤话 -> 广粤话 | 我觉得社会企业同个人都有责任 | ||
| 用广粤语说,越地道越好。 | 普通话 -> 广粤话 | 你嚟探我,我真系好感动,好耐冇见你啦! | ||
| 以广粤话的口语风格来表达。 | 普通话 -> 广粤话 | 快啲啦,唔好再拖拖拉拉,大家都等紧你开会呀 | ||
| 方言:川渝话 | 川渝话 -> 川渝话 | 你要自己打扮,不穿咋个晓得穿起漂不漂亮嘛?看我们这新款多时尚。 | ||
| 方言:川渝话 | 川渝话 -> 川渝话 | 赛尔号那个时候,才出来的时候,还是他那个机制,还是特别好耍的。 | ||
| 请用川渝话表达 | 川渝话 -> 川渝话 | 哎,刚刚晚上想吃点啥子?煮点火锅要得。 | ||
| 模仿川渝话的语气来表达 | 普通话 -> 川渝话 | 你晓不晓得?你啥我都喜欢,嗯,就是有一点不喜欢装。 | ||
| 挑战一下用川渝话的味儿来朗读 | 普通话 -> 川渝话 | 你那哈屋头还有电脑,那时候就已经先进了。 |
跨情绪控制:利用单一中性提示进行跨情绪合成
| Instruction | Input Prompt | Conversion Type | Target Text | TTS Result |
|---|---|---|---|---|
| 情感: 高兴 | 中性 -> 高兴 | If these examinations are held orally, they may be known colloquially as "orals". | ||
| 情感: 愤怒 | 中性 -> 愤怒 | I'm done arguing with you. You're not worth my time! | ||
| 情感: 愤怒 | 中性 -> 愤怒 | In cities, driving speeds are set by which lane a driver is in. | ||
| 情感: 悲伤 | 中性 -> 悲伤 | Everything has changed. The promises and dreams we once had are shattered. How should I face this? | ||
| 情感: 高兴 | 中性 -> 高兴 | But it does not allow for adding new members to interfaces. | ||
| 情感: 愤怒 | 愤怒 -> 愤怒 | 港湾道是每年农历新年举行的香港新春花车巡游的路线之一。 | ||
| 情感: 悲伤 | 悲伤 -> 悲伤 | 我觉得自己好像在黑暗中迷失了,再也找不到出口了。 | ||
| 情感: 高兴 | 中性 -> 高兴 | 我竟然抢到了陈奕迅的演唱会门票!太棒了!终于可以现场听一听他的歌声了! | ||
| 情感: 悲伤 | 悲伤 -> 悲伤 | 我们俩从一开始就君子之交,都说好啦,背信弃义出尔反尔的是她,我告诉你这件事我是受害者。 | ||
| 表达时要悲伤一点。 | 悲伤 -> 悲伤 | 有些软体开发者也注意到软体度量已成为软体开发过程中的一部份。 | ||
| 把这件事说得高兴一点。 | 高兴 -> 高兴 | I bought my first mountain bike with my own earnings, a Merida Warrior 500! Go me! | ||
| 表达时,请务必流露出高兴的情感。 | 中性 -> 高兴 | I ran into a teacher I hadn't seen in years at the coffee shop today. He still remembered me, and we talked about so many fun memories. |
内置精品音色: 内置100+高品质音色
| Instruction | Describe | Target Text | TTS Result |
|---|---|---|---|
| 克隆一下灵小甄的说话腔调。 | 销售、直播带货: 声音明亮清脆,语速轻快且充满活力,语气中带有强烈的推荐感和亲和力,典型的带货主播风格。 | 这款产品的名字,叫变态坑爹牛肉丸。 | |
| 模仿灵梦的风格。 | 虚拟恋人: 充满糖分的高甜少女音,语气娇憨任性,完美演绎了想要人陪伴时的撒娇状态。 | 认为在中文歌曲里,夹杂几句英文就很时髦。 | |
| 麻烦学一下灵岩的口音 | 新闻、客服: 声音清晰正式且专业 | 届时会按照原定计划,与国防部签署相关以地换地协议。 | |
| 克隆一下灵娇的说话腔调。 | 邻家女孩、女大学生、Vlog博主: 清甜明亮的少女音,语感轻快活泼,在讲述生活趣事时充满画面感与青春朝气,极具感染力。 | 总裁问,刚才皮皮鲁唱的歌是谁的词谁的曲,大手笔呀。 | |
| 克隆一下妩媚妲己的说话腔调。 | 妩媚角色: 声音甜美清脆,语调轻盈上扬,表现性感妩媚 | 新娘是一位俄国公主,坐着六只驯鹿拉的雪车,从芬兰一路而来。 | |
| 克隆一下灵绮木的说话腔调。 | 透着刻薄与傲慢的冷艳御姐音 | 这就是它第二个特色——灵活的音色设计能力,你可以直接用文字描述,比如"知性女主播的声音",它就能给你生成。要是懒得想,它还内置了一百多种精品音色,什么动漫角色、短视频配音统统搞定! | |
| 克隆一下灵若虚的说话腔调。 | 老奶奶形象,声音饱含岁月的温暖与慈爱,语速舒缓,透着对生活细节的满足感,极具治愈力。 | 这就是它第二个特色——灵活的音色设计能力,你可以直接用文字描述,比如"知性女主播的声音",它就能给你生成。要是懒得想,它还内置了一百多种精品音色,什么动漫角色、短视频配音统统搞定! | |
| 克隆一下花小呗的说话腔调。 | 儿童角色,声音清脆甜美,带有明显的幼态特征,语调轻快活泼 | 这就是它第二个特色——灵活的音色设计能力,你可以直接用文字描述,比如"知性女主播的声音",它就能给你生成。要是懒得想,它还内置了一百多种精品音色,什么动漫角色、短视频配音统统搞定! | |
| 克隆一下灵浅忧的说话腔调。 | 小男孩,声音清脆明亮,充满元气 | 今天天气不错,要出去玩了。 |
音色创造: 通过自然语言描述零样本合成自定义音色
| Instruction | Target Text | TTS Result |
|---|---|---|
| 性别: 女童声音. 音高: 音高尖锐,持续偏高. 语速: 语速迅捷,语气急促. 音量: 音量响亮,情绪饱满. 年龄: 学龄儿童. 清晰度: 吐字清晰,发音用力. 流畅度: 表达流畅,伴强调性重复. 口音: 标准普通话. 音色质感: 童声清亮,略显尖锐. 情绪: 激动委屈,带有抗议. 语调: 声调高昂,语势急切. 性格: 急躁率真,不甘示弱. | 人家从那走过,他们就说我故意偷听,还说我是小广播,我偏要广播,偏要广播偏。 | |
| 性别: 男性. 音高: 男性沉稳中低音. 语速: 语速舒缓,有自然停顿. 音量: 正常谈话音量. 年龄: 中老年男性. 清晰度: 吐字清晰,发音标准. 流畅度: 言语连贯,表达自然. 口音: 标准普通话. 音色质感: 音质温和,略显沧桑. 情绪: 饱含不舍与怀念,转为平静嘱托. 语调: 前段感叹意味,后段请求意味. 性格: 念旧重情,温和坦诚. | 这就是天望娃娃送给我的我一直舍不得丢掉它,你替我上交了吧。 | |
| 性别: 男性语音特征. 音高: 男性中低音域,初始疑问时音调上扬. 语速: 整体偏快,表述急切清晰. 音量: 正常交谈音量,偶有强调加重. 年龄: 青年至中年男性. 清晰度: 吐字清晰,发音标准. 流畅度: 叙述流畅,偶有为强调而设的短暂停顿. 口音: 带有北方地区特征的普通话. 音色质感: 声音较为浑厚,略带一丝沙哑质感. 情绪: 从关切疑问过渡到解释性陈述,略显急切. 语调: 初始疑问扬起,后转为肯定叙述语调. 性格: 显得坦率直接,急于说明情况. | 没有欺负这孩子呢,报告团长没人欺负他,不是怎么的,他本来是给他师父小杨上门的,回来,就说鬼鬼的鬼。 | |
| 性别: 女性. 音高: 女性高音,句末随情绪上扬. 语速: 语速偏缓,充满恳切感. 音量: 音量正常,激动处略有提高. 年龄: 中年女性. 清晰度: 吐字清晰,略带哭腔. 流畅度: 整体流畅,因情绪略显迟缓. 口音: 标准普通话. 音色质感: 音色略显沙哑,蕴含悲伤. 情绪: 悲伤焦虑,带有不解与恳求. 语调: 起伏较大,表达焦急质问. 性格: 情感浓烈,忧心忡忡. | 我们家好容易恢复成这个样子,你明知有危险,为什么还一定要拉着杉杉? | |
| 用活泼的童声带着喜悦和兴奋不间断地讲述一个有趣的故事。 | 我有个大哥叫小王,能吃饭也能喝汤,别看他手里没武器啊,说话赛过歪白的机关枪。 | |
| 这是一个粤语地区长辈的声音,是一种带有地域特色的创意风格。他使用粤语(广东话),年长男性声音沉厚,语速较慢。语气在说教时显得严肃,但言语间仍透露出对家人的关心。 | 做人呢,最紧要就係开心。 | |
| 这是一个粤语地区长辈的声音,是一种带有地域特色的创意风格。他使用粤语(广东话),年长男性声音沉厚,语速较慢。语气在说教时显得严肃,但言语间仍透露出对家人的关心。 | 你睇你,成日挂住玩,书又唔读。 | |
| 是一个粗犷豪放的东北大哥的声音,是一种极具地域辨识度的创意与特殊风格。他使用带有浓郁东北口音的普通话,中年男性声音洪亮,嗓门大。说话直来直去,语速快,语气中充满了幽默感和不拘小节的豪爽。 | 哎呀我的妈呀,这嘎冷的天儿,你穿这点儿? | |
| 这是一种ASMR耳语,属于一种旨在引发特殊感官体验的创意风格。这个女性使用轻柔的普通话进行耳语,声音气音成分重。音量极低,紧贴麦克风,语速极慢,旨在制造触发听者颅内快感的声学刺激。 | 放松……现在……闭上你的眼睛…… | |
| 这是一种ASMR耳语,属于一种旨在引发特殊感官体验的创意风格。这个女性使用轻柔的普通话进行耳语,声音气音成分重。音量极低,紧贴麦克风,语速极慢,旨在制造触发听者颅内快感的声学刺激。 | 听……这个声音……是不是……很舒服…… | |
| 这是一个体育赛事激情解说员的声音,是极具感染力的创意与特殊风格。他使用高亢的普通话,中年男性声音沙哑(因长时间呐喊)。语速快如机枪,在关键时刻会瞬间爆发,语调充满了紧张、激动和不可思议的情绪。 | 球进了!进了进了进了!伟大的胜利! | |
| 这是一个宫斗剧中的威严皇后的声音,展现了充满张力的戏剧叙事风格。她使用雍容华贵的普通话,中年女性声音沉稳。语速雍容和缓,但每个字都掷地有声,语气表面波澜不惊,实则暗藏锋芒和久居上位的威压。 | 妹这话,是说给本宫听的吗? | |
| 这是一个宫斗剧中的威严皇后的声音,展现了充满张力的戏剧叙事风格。她使用雍容华贵的普通话,中年女性声音沉稳。语速雍容和缓,但每个字都掷地有声,语气表面波澜不惊,实则暗藏锋芒和久居上位的威压。 | 放肆!在本宫面前,岂容你如此喧哗? | |
| 这是一个古装剧中的腹黑反派的声音,充满了戏剧性的叙事张力。他使用华丽而阴柔的普通话,青年男性声音说话时语速慢条斯理,语气看似温和,却在句尾带着一丝不易察觉的冷笑和威胁,让人不寒而栗。 | 呵呵,看来,你还是不太明白自己的处境啊。 |
播客: 多人对话
| Input Speaker1 Prompt | Input Speaker2 Prompt | Target Text | TTS Result |
|---|---|---|---|
| speaker_1: 你可以说一下,就大概说一下,可能虽然我也不知道,我看过那部电影没有。 speaker_2: 就是那个叫什么,变相一节课的嘛。 speaker_1: 嗯。 speaker_2: 一部搞笑的电影。 speaker_1: 一部搞笑的。 | |||
| speaker_1: 所以你想成功的话,就推荐你看这些书。 speaker_2: 我会有时间去看一看的。 speaker_1: 要是像我看的话,我就会感觉特别的。 speaker_2: 枯燥。 speaker_1: 对枯燥无聊毕竟是古文也看不懂除非那些。 | |||
| speaker_1: 知道家长在考虑什么让家长也知道孩子们在考虑什么。 speaker_2: 对。 speaker_1: 减少矛盾。 speaker_2: 对,就是感觉其实出这些电影或者电视剧,也是挺好的让彼此更加了解一下,我感觉如果是一个家长和一个小孩儿,去看电视剧的话,收获也是蛮多的。 speaker_1: 那你还有什么比较好的电影介绍给我呢。 | |||
| speaker_1: 上个厕所,然后那有专门的人给你,就是你上厕所之前,专门有个人给你递纸了。 speaker_2: 对,上个厕所会出来给你递毛巾。 speaker_1: 啊对,让你去擦手这些什么的。 speaker_2: 是的。 speaker_1: 服务,服务非常周到,不过也有少数人就说,这个服务实在太久了,就是,就,就是像那种,就是那个。 | |||
| speaker_1: 什么东西啊? speaker_2: 叫那个的哪吒的那个。 speaker_1: 啊,那个哪吒,但是我没有去看一看嘛。 speaker_2: 我也没看过。 speaker_1: 我当时好像是本来是要去看的。 | |||
| speaker_1: 啊,我吃过。 speaker_2: 是不是。 speaker_1: 因为我之前去过山东一次吃过人家那杂粮煎饼。 speaker_2: 反正跟咱们这儿,不一样是吧,正宗的人家那是正宗的。 speaker_1: 本地的。 | |||
| speaker_1: 那就之前的妆都毁掉了。 speaker_2: 嗯,是是是。 speaker_1: 然后之后就是睫毛。 speaker_2: 哦,对,那睫毛涂睫毛膏。 speaker_1: 画睫呃涂睫毛的时候,先夹一下睫毛,夹。 | |||
| speaker_1: 嗯哪三个字。 speaker_2: 足力健。 speaker_1: 哦听说过。 speaker_2: 那你给我讲讲。 speaker_1: 我听说这个足力健对老年人的脚底有好处,而且边走路都能健身是吗。 | |||
| speaker_1: 就这样子,嗯,一般男生都是看什么电影啊? 推理的吗? 还是什么。 speaker_2: 也不是吧,就是看那种,嗯,具体也说不出哪种类型嘛。 speaker_1: 具体也说不出。 speaker_2: 嗯。 speaker_1: 就是都有看一点。 | |||
| speaker_1: 是了,只有你,化化起妆了才能充实呢,自信心呃然后才,感觉自己的心情是美美哒的。 speaker_2: 你想化妆是,呃那就从眉毛开始说不是从打底开始说吧。 speaker_1: 嗯说,好想听呢。 speaker_2: 洁面以后就是拍水乳,水乳霜。 speaker_1: 嗯。 |
音乐生成
| Instruction | TTS Result |
|---|---|
| Genre: 迪斯科. Mood: 活力四射 / 精力充沛. Instrument: 电吉他. Theme: 运动. Duration: 30s | |
| Genre: 当代古典音乐. Mood: 温暖 / 友善. Instrument: 合成拨弦. Theme: 节日. Duration: 60s. | |
| Genre: 电子舞曲. Mood: 自信 / 坚定. Instrument: 架子鼓. Theme: 节日. Duration: 47s. | |
| Genre: 独立民谣. Mood: 鼓舞人心 / 充满希望. Instrument: 合成铜管乐器. Theme: 节日. Duration: 63s. | |
| Genre: 流行摇滚. Mood: 温暖 / 友善. Instrument: 低音鼓. Theme: 旅行. Duration: 76s. | |
| Genre: 电子舞曲. Mood: 快乐. Instrument: 定音鼓. Theme: 好时光. Duration: 61s. | |
| Genre: 流行乐. Mood: 温暖 / 友善. Instrument: 合成铜管乐器. Theme: 庆典与喜悦. Duration: 41s. | |
| Genre: 当代古典音乐. Mood: 鼓舞人心 / 充满希望. Instrument: 合成拨弦. Theme: 庆典与喜悦. Duration: 45s. | |
| Genre: 电子舞曲. Mood: 鼓舞人心 / 充满希望. Instrument: 电吉他. Theme: 运动. Duration: 94s. |
语音/音乐单通道生成:单通道语音和音乐生成
| Instruction | Input Prompt | Target Text | TTS Result |
|---|---|---|---|
| Genre: 电子舞曲. Mood: 活力四射. Instrument: 合成铜管乐器. Theme: 运动. SNR: 5.0dB. | 全神贯注,跟上这强劲的节奏,冲向终点吧! | ||
| Genre: 流行摇滚. Mood: 快乐. Instrument: 电吉他. Theme: 旅行. SNR: 5.0dB. | 阳光洒满公路,带上行囊,出发去远方! | ||
| Genre: 迪斯科. Mood: 兴奋. Instrument: 架子鼓. Theme: 生日. SNR: 5.0dB. | 派对时刻到!让我们在鼓点中祝你生日快乐! | ||
| Genre: 电子舞曲. Mood: 兴奋. Instrument: 合成铜管乐器. Theme: 运动. SNR: 5.0dB. | 汗水在燃烧,感受这股能量,你就是最强的! | ||
| Genre: 流行摇滚. Mood: 活力四射. Instrument: 架子鼓. Theme: 旅行. SNR: 5.0dB. | 踏上未知的旅程,每一步都充满未知的惊喜! | ||
| Genre: 迪斯科. Mood: 快乐. Instrument: 电吉他. Theme: 生日. SNR: 5.0dB. | 吹灭蜡烛前,先跟着旋律尽情摇摆吧! | ||
| Genre: 电子舞曲. Mood: 快乐. Instrument: 合成铜管乐器. Theme: 生日. SNR: 5.0dB. | 这是属于你的闪耀时刻,生日派对正式开始! | ||
| Genre: 流行摇滚. Mood: 兴奋. Instrument: 电吉他. Theme: 运动. SNR: 5.0dB. | 超越极限,感受心跳的轰鸣,永不言弃! | ||
| Genre: 迪斯科. Mood: 活力四射. Instrument: 架子鼓. Theme: 旅行. SNR: 5.0dB. | 在霓虹闪烁的异国街头,找寻失落的快乐! | ||
| Genre: 流行摇滚. Mood: 快乐. Instrument: 合成铜管乐器. Theme: 运动. SNR: 5.0dB. | 运动让生活更有趣,让我们一起快乐出发! |
音效生成
| Instruction | TTS Result |
|---|---|
| A motor is revving and changing gears | |
| Thunder and a gentle rain | |
| Continuous snoring of a person | |
| Nature sounds with a frog croaking | |
| A man talking as a stream of water trickles in the background |
语音/音效单通道生成:单通道语音和音效生成
| Instruction | Input Prompt | Target Text | TTS Result |
|---|---|---|---|
| Birds chirping | 副主任及以上号别就诊人次,为二百零八点二万。 | ||
| Light rain | 其中又有大部分百分之四十一点九认为,由该品牌影楼拍摄。 | ||
| Keyboard typing | 本次有害昆虫科普展,是一场专门为孩子准备的科普教育活动。 | ||
| Fire engine siren | 他陪舅舅到简阳一所学校,考察捐资改建事宜。 | ||
| Rainstorm | 请语音留言,告诉电话精灵您没有达到父母的哪些要求。 |


 图1:(a) 现有模型使用分离的视觉表征。(b) MingTok 使用统一方案生成语义与生成表征。(c) 这种统一方法带来了超过 3.5 倍的训练收敛加速。
图1:(a) 现有模型使用分离的视觉表征。(b) MingTok 使用统一方案生成语义与生成表征。(c) 这种统一方法带来了超过 3.5 倍的训练收敛加速。 图 2:在通用识别任务上,我们的方法性能接近分离表征模型,并显著优于其他统一表征模型。在生成方面,我们的模型在颜色、位置等细粒度控制上表现出明显优势。
图 2:在通用识别任务上,我们的方法性能接近分离表征模型,并显著优于其他统一表征模型。在生成方面,我们的模型在颜色、位置等细粒度控制上表现出明显优势。 图3:在使用统一的 MingTok 表征进行联合训练时,其性能与纯生成训练的差距极小,证明了统一方案的优越性。
图3:在使用统一的 MingTok 表征进行联合训练时,其性能与纯生成训练的差距极小,证明了统一方案的优越性。 图4:“超分→上色”和“分割→编辑”等多轮任务,现在可以在一个无缝的流程中完成。
图4:“超分→上色”和“分割→编辑”等多轮任务,现在可以在一个无缝的流程中完成。











 Given the following instructions: little girl, pink, your monitors colors off friend p pink shirt girl; please perform referring segmentation on this image.
Given the following instructions: little girl, pink, your monitors colors off friend p pink shirt girl; please perform referring segmentation on this image.





 这张图片看起来设计感很强烈,可以详细描述一下它的各个设计元素?
这张图片看起来设计感很强烈,可以详细描述一下它的各个设计元素? 图中的书法为什么好?
图中的书法为什么好? 图中这款手机适合给父母买吗?
图中这款手机适合给父母买吗? 如何使用图中软件购买机票?请列出具体操作步骤
如何使用图中软件购买机票?请列出具体操作步骤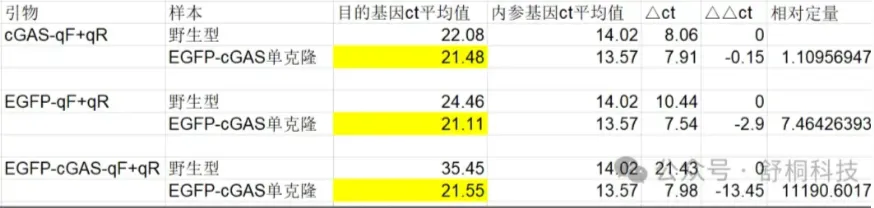 根据图表计算样本之间的 Δct 在哪一个引物下相差最小? | 根据图表计算样本之间的 Δct 在 cGAS-qF+qR 引物下相差最小。(图片来源:互联网公开-舒桐科技公众号)
根据图表计算样本之间的 Δct 在哪一个引物下相差最小? | 根据图表计算样本之间的 Δct 在 cGAS-qF+qR 引物下相差最小。(图片来源:互联网公开-舒桐科技公众号)